



Have you ever worked on a codebase with a deficiency everyone knew about, but that you could never quite justify fixing? The kind of thing where the right move is obvious, the cost is enormous, and it never clears the bar against the next quarter's roadmap. So it just sits there, quietly taxing everything you build on top of it.
For most of Omnea's four years, that thing was Hasura. Over about six weeks, a single tiger team of engineers rewrote a fifth of our backend to take it out of the critical path, moving every production data access onto a typed data layer we own, built on Kysely. There's hope on the horizon for these projects, and this is the story of why.
Why Hasura had to go
Let me be clear up front: Hasura was the right call when we made it. As an early-stage startup we were optimising for one thing, speed of execution, and Hasura is essentially a backend-as-a-service. Point it at Postgres and you get an instant GraphQL API, permissions, and the shortest possible path from schema to shipped feature, all with a tiny team. It did exactly what we needed.
But the things that make a tool great for a five-person team aren't the things that make it great for a platform serving large, demanding customers. As our data model and complexity grew, three problems became hard to ignore:
- No fine-grained control over transactions. A workflow that should be one atomic unit got expressed as several GraphQL mutations, with no clean way to wrap them in a single transaction.
- Latency on every call. Hasura sat in front of the database and added overhead to essentially every request, plus query-generation patterns that weren't obvious from the application layer. Diagnosing a slow request meant tracing through several layers of abstraction before you understood what actually hit Postgres.
- It coupled our uptime to a third party. Hasura was in the middle of nearly every request. When something went wrong, the fix often wasn't in our hands, and every incident came with an extra question attached: was this us, the GraphQL layer, permissions, query generation, or the database?
Eventually the conclusion was unavoidable: continuing to scale Omnea meant owning this layer ourselves.
Choosing the replacement
The first real decision was ORM vs. query builder. We took it slowly and evaluated the field properly, building proof-of-concept clients for Prisma, Drizzle, Knex, MikroORM, and Kysely against our actual schema rather than going off docs.
The ORMs each fell down somewhere that mattered to us. Prisma's RLS and check-constraint support was incomplete and it generated a 30MB types file off our schema. Drizzle couldn't even introspect our schema cleanly and felt like a project stalled mid-flight (this seems to have changed now). MikroORM was genuinely nice in places, but added ~50ms+ to cold starts for its metadata cache, was painful to deploy, and its implicit unit-of-work made it hard to keep every query inside our tenant-isolating transaction.
We landed on Kysely: a lightweight, type-safe SQL query builder. We pick it for three reasons: flexibility, simplicity, and full control. It doesn't try to hide SQL from you; it generates types straight from the database schema, so the query you read in the handler is the query that hits Postgres, type-checked end to end. Two side effects turned out to matter more than expected:
- It's a near-perfect fit for Lambda, with almost no runtime overhead beyond the driver, so cold starts stay small.
- Because it reads like SQL, AI agents are dramatically more effective with it than with a heavy ORM's bespoke abstractions. That mattered more than we realised going in.
How we actually did it
There was never going to be a big-bang cutover. Hasura was woven through the whole platform, so we replaced it by endpoint and by domain, while keeping the contracts identical and controlling rollbacks with feature flags. We already had a REST layer in front of the same Aurora Postgres database, so this wasn't about standing up new endpoints.
Patterns first, then volume. Before touching the bulk of the work, we spent time getting the patterns right on new endpoints and a handful of early services. Out of that came two things that made the rest possible: a Claude skill encoding the migration playbook, and a GraphQL-to-Kysely code generator that parses a .graphql file and emits the equivalent typed Kysely query. Together they let us migrate services reliably with minimal supervision: codegen for the mechanical translation, the skill for transactionality, test coverage, feature-flag gating, and scope decisions.
Each domain then followed the same loop:
- Migrate in place behind a feature flag that could route each request to either the Hasura or the Kysely path, or cut straight across for low-risk domains.
- Run in parallel with the old path, comparing latency, error rates, and timeouts on live traffic, split by flag value.
- Bake for a week or two, with instant rollback the whole time.
- Flip fully once the metrics held.
We also moved Hasura's events and actions onto an outbox pattern over native messaging (SQS/SNS/EventBridge), keeping response shapes stable so clients mostly didn't have to change as each domain flipped.
The part we were most nervous about: authorisation
Permissions were the riskiest thing about leaving Hasura. There, authorisation lived in metadata: role rules sitting between the app and the data. Getting that wrong mid-migration isn't a slow page; it's one tenant seeing another tenant's data, about the most serious mistake we can make. We did not want isolation living in handler code that someone could forget to apply.
So we pushed it down into Postgres itself with Row-Level Security. Every request runs in a short transaction that pins the tenant before any query executes, and each tenant-scoped table carries a policy the database enforces automatically:
ALTER TABLE some_table ENABLE ROW LEVEL SECURITY;
ALTER TABLE some_table FORCE ROW LEVEL SECURITY;
CREATE POLICY tenant_isolation ON some_table
USING (organisation_id = current_setting('app.organisation_id', true)::uuid)
WITH CHECK (organisation_id = current_setting('app.organisation_id', true)::uuid);
await db.transaction().execute(async (trx) => {
await sql`SET LOCAL app.organisation_id = ${ctx.organisationId}`.execute(trx)
// every query here already runs with tenant context + guardrails applied
})
A handler that forgets to filter by tenant doesn't leak data. The database refuses. The rules that matter most now live as close to the data as they can get.
Where the real bottleneck turned out to be
Once the patterns and tooling were solid, writing the migrations stopped being the hard part. The bottleneck became team-specific domain knowledge and code review: knowing what each query was for, and reviewing the change confidently. So we spun up a tiger team with a representative from each product team, pulling the horizontal knowledge into one group running the remaining-query count down to zero on a dashboard everyone could watch.
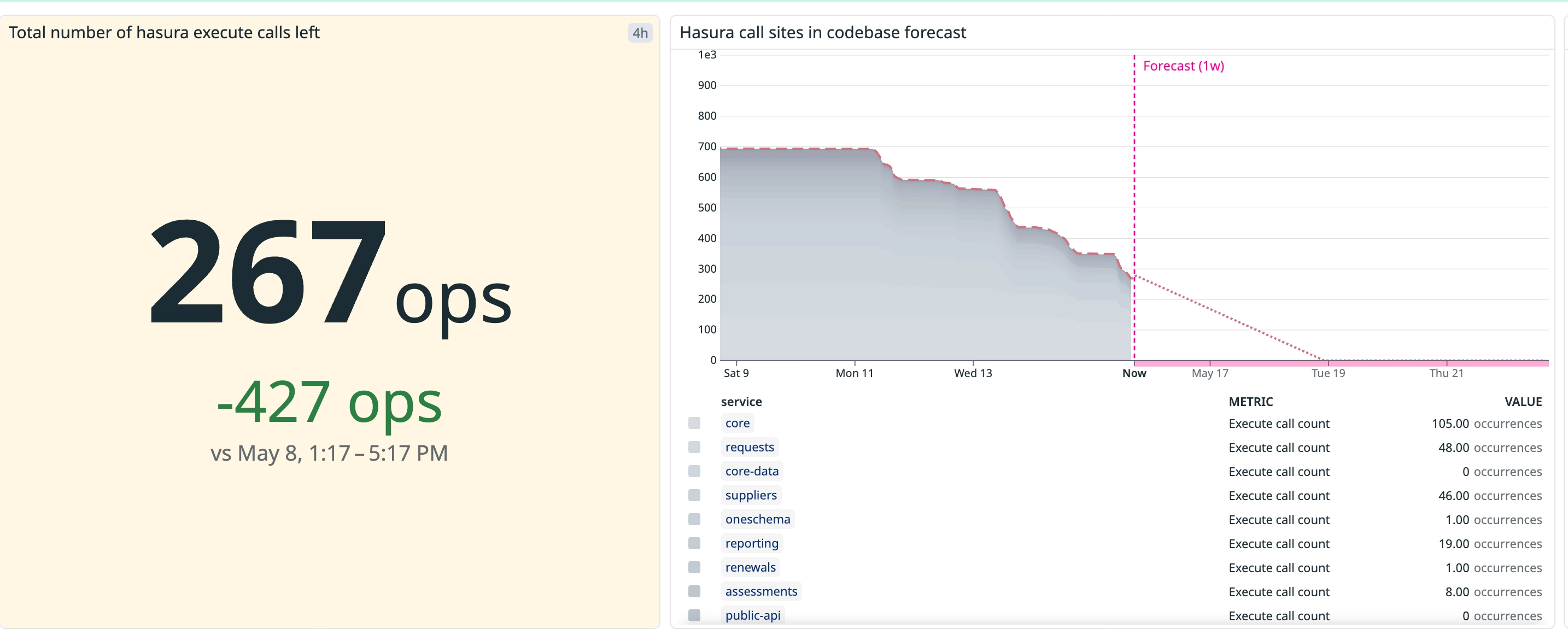
The results
By the time the last domain moved over, Hasura was drained out of the critical path, and the numbers held up.
- 1,232 → 0 Hasura call sites in production code.
- Hasura's share of live production DB queries: ~48% → under 0.1%.
- API latency, blended across all routes: p50 ~200ms → ~130ms (−35%), p95 ~460ms → ~310ms (−33%).
- The big wins are at the tail. Medians improved modestly (30–70%), but P95/P99 improved 10×+. Pre-cutover, the worst 1% of requests routinely hit the ~29s Lambda timeout; afterwards P99 sits in the low seconds. One endpoint's P95 went 5.2s → 0.41s (−92%).
- Database latency dropped too: commit latency −62%, read latency −60%. And crucially, deadlocks stayed flat. Consolidating many Hasura mutations into single transactions is exactly the kind of change that can increase contention but it didn't.
- The codebase got smaller. 461 PRs and 263k lines of churn netted a subtraction of 5k lines while increasing test coverage: Kysely replaced GraphQL docs, generated types, and resolver plumbing with less code.
- 6
fixcommits across all 461 PRs. The flags + tests + burn-down dashboard kept production boring throughout.
What it taught us
Two things stand out.
AI changes which projects are possible within the constraints of a fast moving startup. A rewrite this size would have cost a team like ours six months minimum the old way, and a six-month foundational project with no new customer-facing button at the end of it almost never gets business buy-in. With modern AI tooling it took a fraction of that, and the bottleneck shifted from writing code to reviewing it. That genuinely changes the calculus. The deficiencies you used to have to live with because the fix was untenable are suddenly back on the table. We are, to put it bluntly, free from the shackles of old choices.
The more critical a system is, the more it's worth owning. Renting your backbone from a third party is a great trade early on. Past a certain scale it stops being one. Bringing this layer in-house didn't just make us faster. It made the whole system something we can reason about, debug, and build on, on ground far stronger than what we started with.
We're growing the Platform team in London. If owning foundations like this, rather than renting them, is your kind of problem, we'd love to hear from you.




