



When backend systems grow, complexity creeps in from everywhere, i.e. External APIs, Infrastructure concerns or Business logic changes.
Left unchecked, this complexity compounds. Features become slower to build. Bugs appear in unexpected places. Refactors become risky. You end up with a big ball of mud.
At Omnea we try to design systems so the opposite happens: Velocity should increase as a system grows.
Recently we built a Continuous Monitoring service for Third-party Risk Management. It turned out to be a great example of how we approach backend architecture.
This article walks through how we structured the system and why it has worked well.
The Problem: Continuous Supplier Risk Monitoring
The service continuously scans suppliers for risk signals like:
- Sanctions (i.e. Governments banning doing business with a supplier)
- Adverse media articles
- Politically exposed persons
- Regulatory actions affecting the supplier
Data comes from multiple trusted third-parties like Dow Jones. They all expose complex APIs.
Every day the system:
- Checks supplier profiles with external providers
- Retrieves new risk alerts and categorises them
- Surfaces them in the product UI
A simplified UI example from the product is shown here.
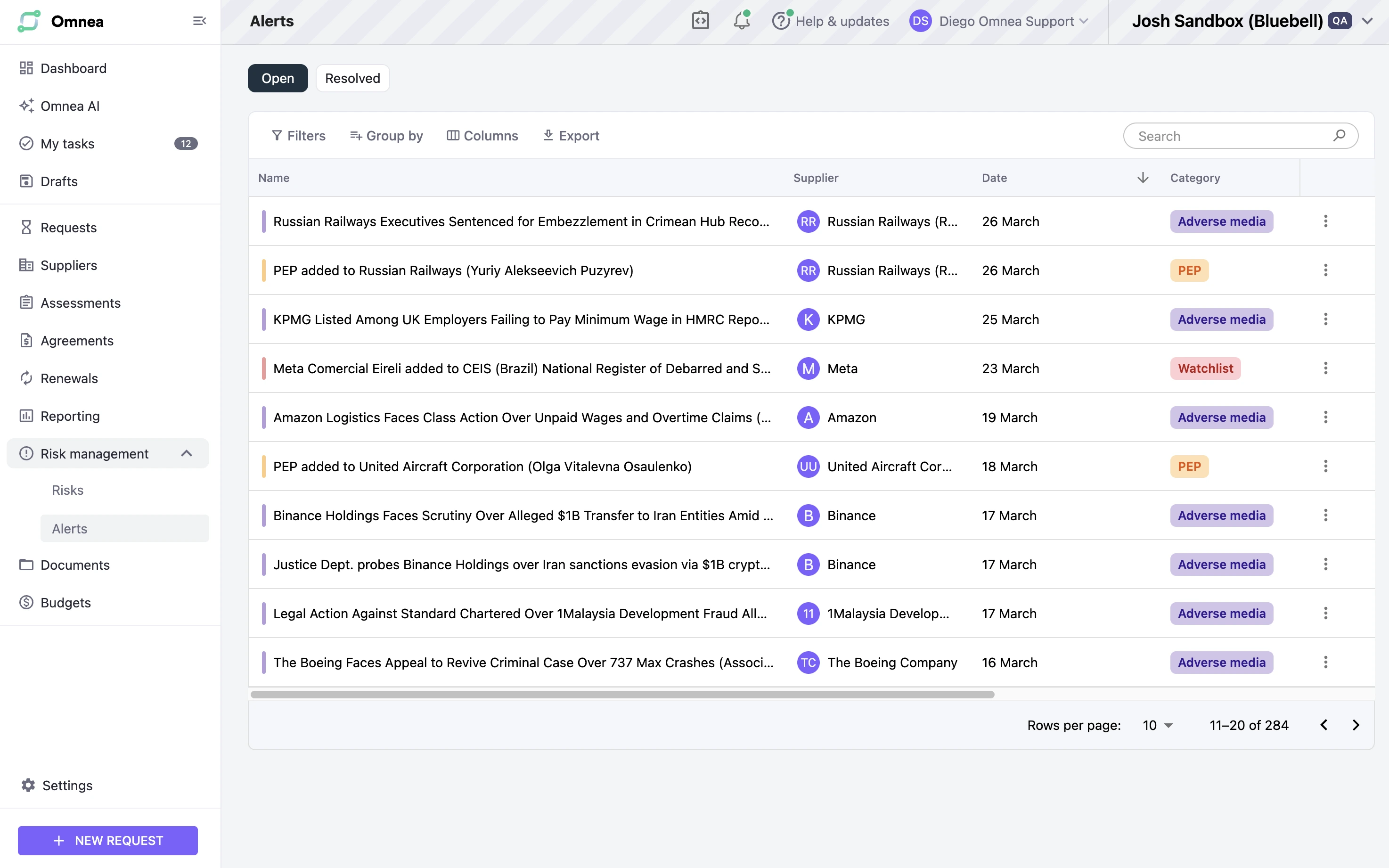
This sounds manageable — until you consider the real constraints.
Each provider has:
- Different APIs
- Different data formats
- Evolving schemas
Meanwhile the product (Omnea) keeps evolving:
- New business requirements
- Needs to aggregate data across multiple providers
- Need for the system to integrate with other services like audit logging or messaging
Without clear boundaries this kind of system quickly becomes tangled and unmaintainable.
So before writing much code, we focused on the architecture. Here is what we came up with.
The Architectural Principle
We based the service on Ports and Adapters (Hexagonal Architecture) and in the SOLID principles for software design.
The core idea: Business logic should not depend on external details. Instead the application relies on abstractions (ports) and the outside world implements these via adapters.
A simplified diagram of the architecture looks like this:
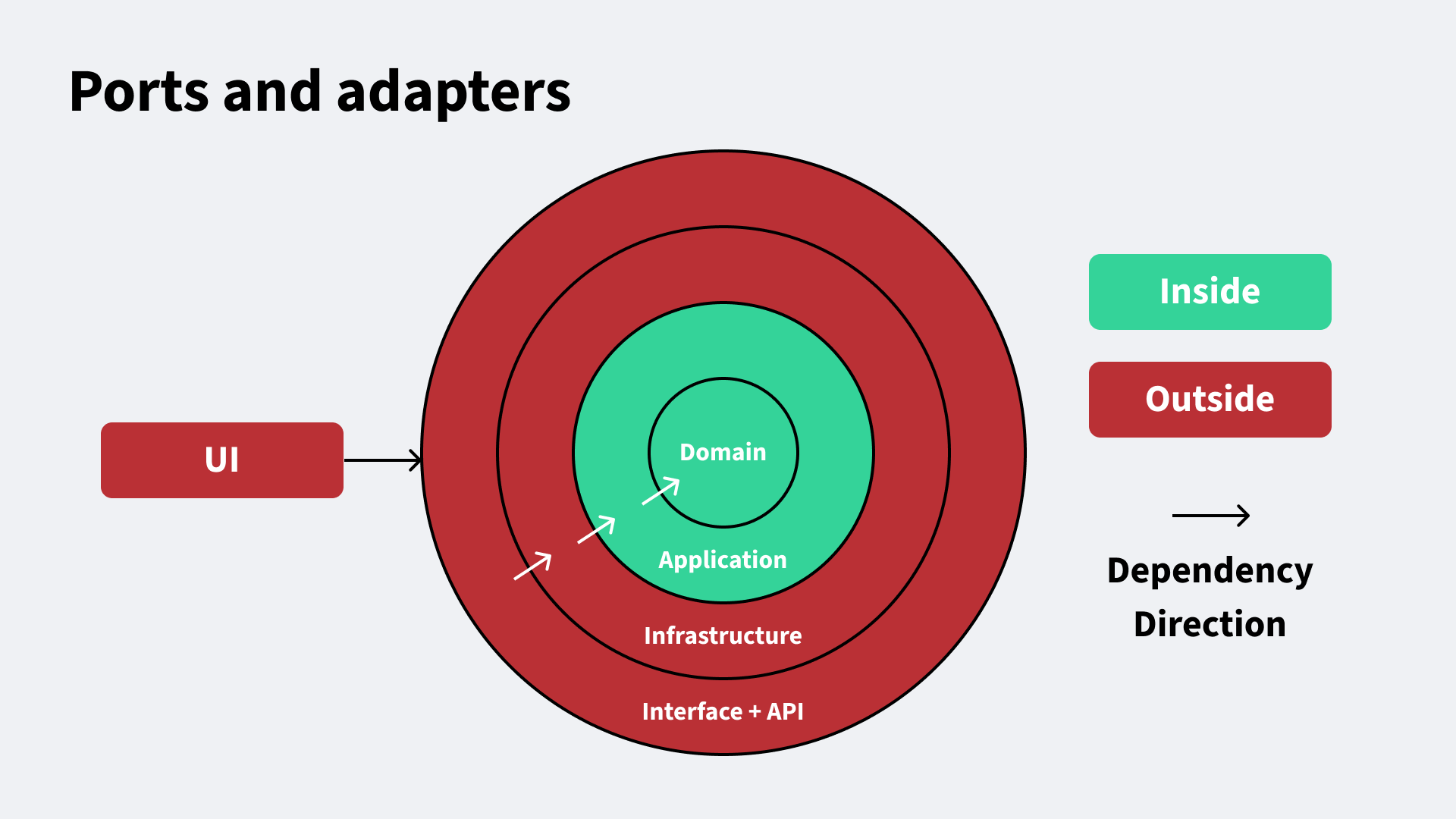
In this diagram, dependencies always point towards the domain — the centre of the system
This keeps the business logic isolated from external systems.
Layer 1: The Domain
The domain layer defines the core concepts of the system. Think of it as the source of truth for the system’s concepts.
Because business rules change most often, it makes sense to make this part of the system the easiest to change. That’s why it has no dependencies (other than generic utils).
For example, risk alerts are defined using strongly typed schemas.
import { z } from 'zod'
export const AlertSummarySchema = z.object({
id: z.string().ulid(),
name: z.string(),
orgSupplierId: z.string().uuid(),
assigneeUserId: z.string().uuid().optional(),
categorisation: CategorisationSchema,
status: AlertStatusSchema,
triggeredDate: z.date(),
})
And business rules apply pure logic. Think Functional Programming with its deterministic behaviour and lack of side-effects.
The domain layer:
- Contains core types and business rules
- Has no external dependencies (i.e. no database models)
- Is stable and easy to test
Layer 2: Application — Ports & Use Cases
Ports
The application layer communicates with the outside world through ports. Ports are simple interfaces describing what the application needs.
Simplified example:
export interface AlertsRepositoryPort {
upsert(data: AlertDetailDto): Promise<AlertDetailDto | ServiceError>
listAll(options: ListOptsDto): Promise<ListResponsePort<AlertSummaryDto>>
getById(id: string): Promise<AlertDetailDto | ServiceError>
}
The application layer depends only on these interfaces that we control, not on specific providers or infrastructure.
I.e. the external APIs and our infrastructure like the database will have to implement the Ports the application defines.
All the ports use DTOs (Data Transfer Objects) as inputs/outputs, providing a common language, closely linked to the domain, that all adapters must map to.
Use cases
The application layer implements use cases. We build one behaviour per use-case (Single-responsibility principle).
You can think of use cases as “business actions” or “user behaviours”. Examples include:
- List risk alerts
- Update risk alerts
- Get an external risk profile from a provider
Each use case is a small function with explicit dependencies.
type Input = {
data: ListAlertsInput
dependencies: {
logger: LoggerPort
alertsRepository: AlertsRepositoryPort
}
}
export const listAlerts = async ({
data,
dependencies: { alertsRepository, logger },
}: Input): Promise<ListAlertsOutput> => {
logger.info('Listing alerts')
return alertsRepository.listAll(data)
}
A few things to notice:
- Dependencies are injected and defined as abstract Ports (interfaces)
- Business logic is isolated
- No infrastructure code appears here
These use-cases follow the Open/Closed principle, because once written they are closed for modification (unless the rules for the use case itself change) but the system is open for extension (new use cases).
This structure makes the system maintainable and unit testing trivial.
const logger = mock<LoggerPort>()
const alertsRepository = mock<AlertsRepositoryPort>()
it('should return a list of alerts', async () => {
alertsRepository.listAll.mockResolvedValueOnce(mockData)
const result = await listAlerts({
data,
dependencies: { logger, alertsRepository },
})
expect(result).toEqual(mockData)
})
Because dependencies are explicit, tests are simple and fast. The application depends on abstractions rather than infrastructure, following the Dependency Inversion Principle.
Since we depend on abstractions, we can inject any mock dependencies that meet the interface. This allows for ultra-fast unit tests since we use mocks rather than real infrastructure. Infrastructure is tested E2E with integration tests instead (more later).
Moreover, any adapter that implements a port can be substituted without changing the application layer, which aligns with the Liskov Substitution Principle.
Layer 3: Infrastructure — Adapters
Adapters implement ports for real systems.
Examples include:
- a Dow Jones provider adapter
- a DynamoDB alerts repository
- Adapters for SQS queues, logging, and many other external providers
For example, the Dynamo repository implements the alerts persistence port.
class DynamoAlertsRepositoryAdapter implements AlertsRepositoryPort {
async upsert(data: AlertDetailDto) { /*...*/ }
async listAll(params: ListAlertsParams) { /*...*/ }
async getById(id: string): { /*...*/ };
}
All the DynamoDB-specific code is encapsulated in this service that consumers can treat as a black box.
If the database changes, we modify the adapter. The application layer remains untouched.
Similarly, we have adapters for all external actors, like the third-party integrations.
Even though all those integrations use different data and APIs, they all map back to our simple Ports and DTO models.
This means we can easily write code against our own business rules and use our own stable data models, rather than depending on changeable third-parties. Our application depends on simple Ports, not on any specific implementation.
Layer 4: Interface Layer
The interface layer exposes the system through APIs.
Its job is very simple:
- Validate input
- Wire dependencies
- Call use cases
In fact we enforce an ESLint rule that interface functions must have cyclomatic complexity of 1, meaning no business logic is allowed here.
This is just a thin layer that our UI can call via endpoints.
Maintaining the project
Great architecture should make it easy to extend the project without undermining its architectural design. This design lends itself to simple maintenance.
We use ESLint rules and module boundaries (enforced via NX) to ensure:
- The domain layer has no dependencies
- Use cases depend on ports, never adapters
- Modules cannot skip layers
These constraints make it hard to accidentally introduce tight coupling and easy to extend the system without having to modify existing use cases (Open/Closed principle).
The Payoff
This architecture has produced several practical benefits.
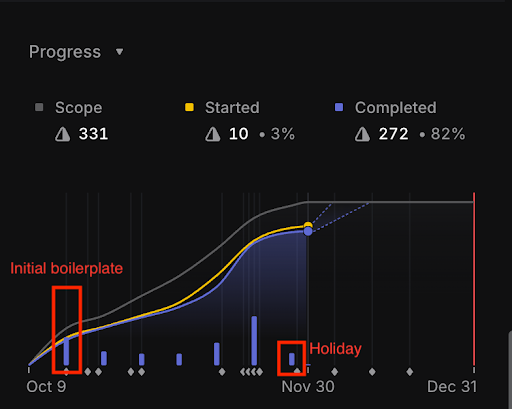
1. Velocity improves over time
The initial setup took about two weeks.
But after that, development sped up each week, eventually hitting four milestones in a single week.
2. New integrations are easy to add
Adding a new risk provider usually means:
- Implementing a new adapter
- Adding mappings
Typical implementation time: ~1 week, as all you have to do is write the code that is specific to the new provider. All the application code remains unchanged, saving time and lowering risk of regressions.
3. Refactors are low risk
Infrastructure changes are isolated.
Examples:
- Database changes affect only persistence adapters
- Provider API changes affect only provider adapters
- Logging upgrades affect one module
4. Parallel development works well
Because modules communicate through clear interfaces, engineers can work independently across modules.
This has been particularly effective with our Nx monorepo setup, where modules act like black boxes.
5. Testing is straightforward
The service currently has:
- ~700 unit tests (100% test coverage on all relevant modules since it’s so easy to test)
- ~70 end-to-end tests
The entire E2E suite runs in roughly 60 seconds.
After a few months of this system running in production we have hardly seen any bugs, given the extensive testing deployed.
6. CI stays fast
We use Nx affected builds so CI runs tasks only for changed modules.
Even as the repo grows, build times stay fast. I.e. if you make a change to the persistence layer, you don’t have to build the application/domain (since they are completely independent of the infrastructure).
7. AI tools reinforce the patterns
We use Claude Code, Cursor, and Copilot at Omnea extensively. These AI tools thrive when the repository has a clear structure and rules.
A problem with these tools is AI slop. Where you get code that works locally, but doesn’t follow the project’s architecture leading to tech debt.
We have found building boilerplate and new features really easy with Claude Code in this service since it has plenty of examples and patterns to emulate.
This has allowed us to ship more maintainable code faster, as AI tools can leverage enough context to emulate previous work in the service.
When This Pattern Works Best
At Omnea, we spend time designing systems to be maintainable and well architected. In this instance, Ports and Adapters worked well, but it is not a silver bullet.
It works best when:
- Business logic is complex
- Systems integrate with many external providers
- The system will evolve for years
There are some drawbacks of this pattern to be aware of:
- Increased complexity, overkill for small services
- More boilerplate code to maintain, like mappers between each layer
- Risk of getting the abstractions wrong or overfitting for a single given provider
We have come up with different designs for other parts of our system. This is just one example of the architecture of one of our most recent services.
Engineering at Omnea
One of our guiding principles at Omnea is craft at speed. We aim to build quality software we can be proud of, whilst being pragmatic and solving real customer problems.
That means:
- Investing early in architecture whilst iterating quickly
- Keeping developer experience fast
- Building maintainable systems that don’t drown us in technical debt later
Because the goal isn’t just to ship software. It’s to build systems where engineering velocity increases over time. Developer experience, paying down technical debt, and improving the design of our existing systems are prioritised at Omnea. If you enjoy thinking about:
- Quality architecture/system design that solves real problems
- Working with ambitious, talented and kind colleagues
- Joining one of the fastest growing startups in Europe
You’ll probably enjoy working here.
We are tackling a lot of interesting problems: complex systems, integrations that must scale, architecture decisions, performance issues with large customers, and AI challenges.
If this resonates with you, you should know we're hiring. Check out our open positions here.



