



AI has not changed software engineering by removing the need for craft. However, it has dramatically increased the speed of execution.
The basic sequence is still recognisable: research, plan, implement, verify. But the leverage within each step has changed. A strong idea can now turn into working code much faster than before. So can a weak one. That's where the upside comes from, but also why the engineering process around the model matters so much.
At Omnea, writing code is only part of the challenge. Just as important is understanding the domain, the system boundaries, the invariants, and the downstream consequences of change. AI has made code generation much faster. As a result, judgement, context, and verification matter more, not less.
Over the past year, we have spent time evaluating how AI-assisted engineering works in a large production codebase. The clearest lesson has been that, once the model is capable enough, most of the gain does not come from syntax generation alone. It comes from the engineering approach around the model. Here is what that has meant in practice.
Context is the speed multiplier
AI can accelerate implementation significantly in the right workflow, and that is becoming more true as models improve. But in day-to-day work on a large codebase, what usually separates a strong result from a mediocre one is whether the model understands the system it’s working in.
This is the basic idea behind context engineering: giving the model the right information at the right point, instead of assuming better prompting will solve the problem on its own. That maps closely to what we’ve seen in practice. In a large codebase, AI is most useful when it has the right context. Sometimes that means avoiding stale material. Sometimes it means removing irrelevant detail. Sometimes it means surfacing the specific files, constraints, and invariants that matter for the change at hand.
When the model understands the system, it can move quickly without sacrificing quality. When it does not, speed is much less valuable.
We tried a range of approaches before settling on what worked best for us. Two failure modes came up repeatedly when we tried to give the model enough system understanding. The first was giving agents too much freedom with too little grounding. That often produced code that looked plausible, but violated important invariants. The second was trying to compensate with large amounts of permanent markdown documentation, much of which went stale quickly. In one case, the model had too little structure. In the other, it had structure that could no longer be trusted.
The process is the same. The leverage has shifted.
A good engineer working with AI can now move through implementation much faster than before. That changes where time and attention are worth spending. Activities that used to consume a meaningful share of time, such as tracing patterns, scaffolding code, writing repetitive glue, and mapping out local structure, can now be done much faster.
That changes where you need to be most deliberate. Planning has always mattered, especially on larger projects. In an AI-assisted workflow, it becomes one of the main ways to keep the work on track. Verification matters too. When implementation is relatively cheap, clarity of intent and a clear path to verification matter much more.
In practice, the workflow that has worked best for us is fairly simple.
Research. Before implementation, we use AI to build task-specific understanding of the codebase as it exists today. We do not rely heavily on generic repository summaries or broad architectural overviews. Instead, we point the model at the codebase, give it a few basic primitives such as file read, search, and grep, and let it investigate. Given the right task and enough room to explore, models are often surprisingly good at building a working understanding of the relevant part of a system.
Plan. We then compress that understanding into an implementation plan: the sequence of steps, the files likely to change, the code-level details that matter, the validation criteria, the risks, the non-goals, and any rollout concerns. This is the step that makes intent reviewable. It gives engineers something concrete to interrogate before code is generated, rather than relying only on the diff once it exists.
Implement. Only then do we move to implementation. At that stage, the model is working from a cleaner context window and a clearer brief. It’s no longer trying to understand the system and generate code at the same time. Separating those steps has made implementation more reliable, and usually faster as well.
Verify. Finally, we make verification explicit. Tests, acceptance criteria, screenshots, logs, edge cases, and rollback considerations are not just after-the-fact checks. They are part of the workflow. One of the most useful things you can do is give the model a clear way to tell whether it is right. Models become much more useful when they can work against a clear spec and then check their own work before a human reviews the diff.
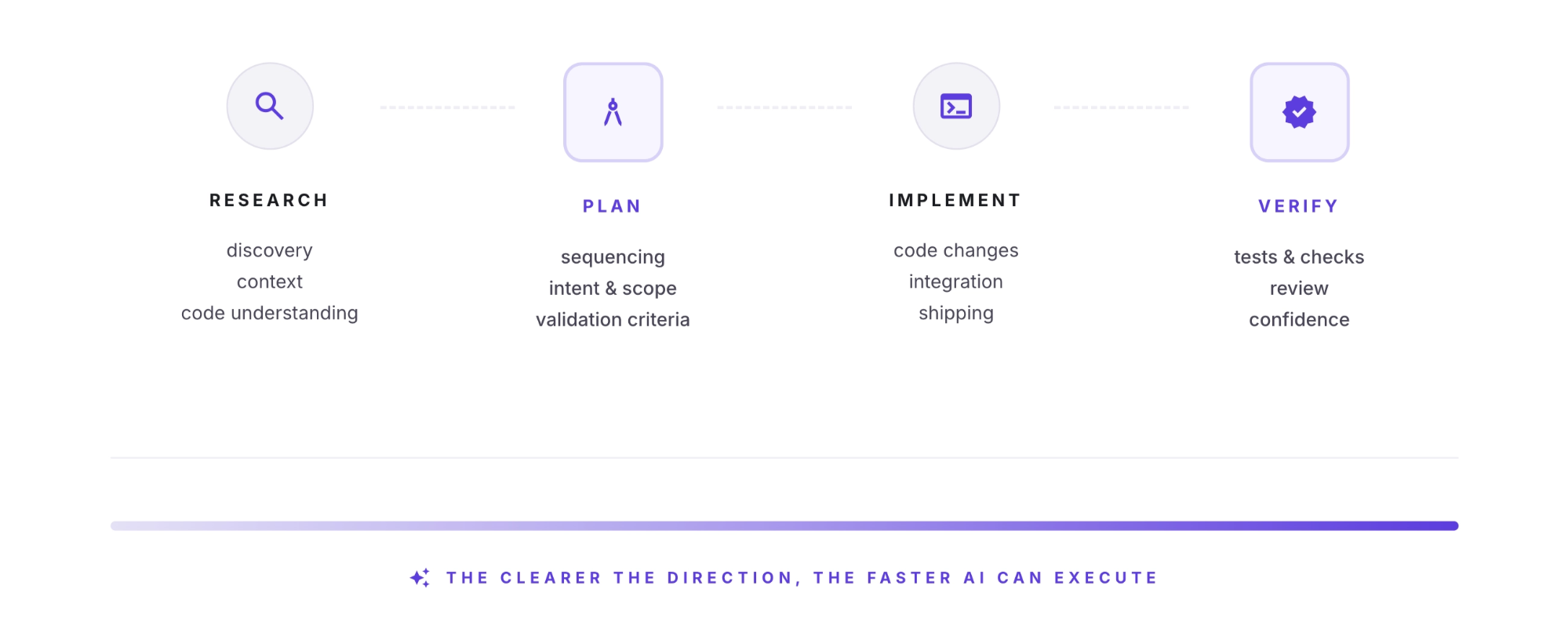
There is nothing especially new about that sequence. What has changed is how much more valuable it becomes when code generation is relatively cheap and implementation speed is high.
Document what lasts. Generate what changes.
One useful distinction for us has been between what should be documented permanently and what should be generated on demand.
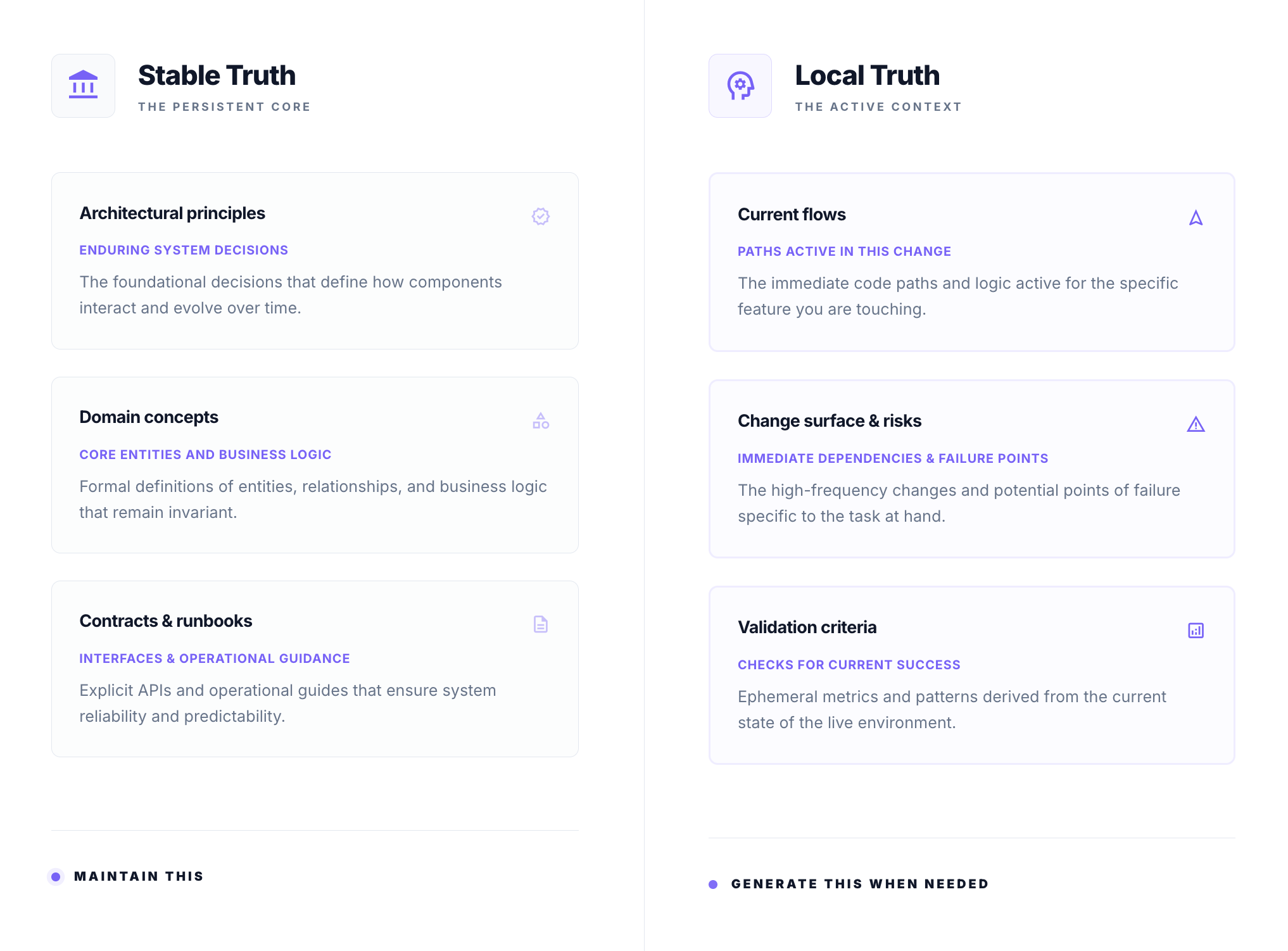
Permanent documentation should capture things that change slowly: architectural principles, domain concepts, contracts, invariants, system boundaries, and runbooks. These are stable truths. They are worth maintaining because they remain useful over months or years, and AI has made them much cheaper to produce and update. Lightweight project instructions, architectural notes, and enduring conventions all fit here.
Everything else is usually better generated at the point of need: which part of the system matters for this change, how a flow works today, which patterns are relevant, and where the real risks and opportunities lie. This is local truth. It shifts with every merged PR. Trying to keep that permanently up to date is usually a losing game.
A good example is CLAUDE.md or AGENT.md files. They are useful for capturing durable guidance: how the repository is organised, which invariants matter, which patterns to follow, and what good looks like in this codebase. They are much less useful as a substitute for task-specific research. Context that depends on the task, recent changes, or local implementation details is usually better discovered fresh.
That distinction also matches how engineers actually work. People do not keep an entire codebase in active memory. They retrieve what they need when they need it. Dynamic research gives models a similar advantage.
For us, that has become a useful rule of thumb: preserve stable truth, generate local truth.
Give the model less noise and more useful structure
One common response to AI is to build elaborate scaffolding around it: custom harnesses, chains of sub-agents, deep tool integration, and long-lived context windows. The instinct is understandable: more tooling ought to produce better results.
In practice, the real question is not whether to add structure, but whether the structure is useful.
Some structure helps a great deal. A good plan helps. So do clear project instructions, reliable tools for search, file reading, diffing, and testing, and clean execution environments. A lot of noisy scaffolding does not.
More often than not, what works best is a smaller set of general-purpose tools and enough freedom for the model to use them well. Given a clearly framed task and room to investigate, models are often surprisingly good at building a working understanding of a codebase.
Every additional tool, integration, or orchestration layer has a cost. It consumes tokens, adds decision points, and gives the model one more way to lose the thread. In larger codebases, those costs add up quickly. Over-engineered workflows often make the model less effective.
The challenge is to add structure without adding noise.
What has made the difference for us
Not every task needs the full process, and the level of rigour should match the level of risk. A copy change does not need a research brief. A cross-domain migration does. The harder the problem, the more context engineering and verification matter.
What we standardise is not every detail of how engineers work with models. It is the artefacts. We want a research brief to answer certain questions. We want an implementation plan to contain certain elements. We want a validation summary to make certain checks explicit. That gives the organisation consistency without forcing everyone into the same editor, model, or interaction style.
For this to work across a team, rather than just for a few people, a few things mattered:
- Teams need some shared direction. Shared direction helps people learn faster and build on what is already working.
- We standardise artefacts rather than tooling. Engineers can use the tools they prefer, but the output needs to be legible to everyone else.
- We prefer dynamic research over large volumes of AI-facing documentation. For most implementation work, fresh task-specific research is more useful than large amounts of permanent markdown that quickly goes stale.
- For anything beyond a small change, we review the plan before implementation. That makes it easier to inspect intent before code is generated, rather than relying solely on review of the final diff.
- For anything non-trivial, we make the verification path explicit up front. It should not start only after the code is written.
The bottom line
Good software engineering has not been replaced. AI does not remove the need for engineering discipline. If anything, it increases the return on discipline.
In production codebases, the differentiator is rarely just access to a stronger model. It is the quality of the context, the clarity of the plan, the strength of the verification loop, and the design of the workflow around the model.
When those things are in place, AI starts to make a real difference to how fast a team can move. It becomes a genuine force multiplier: one that increases engineering speed, expands the scope a team can take on, and helps a company build faster.
That is where we are investing, and it is paying off.
If this thinking resonates with you, check our all our open roles.




