



There's a phase every team building with LLMs goes through. Your feature works in a demo. It handles a handful of test cases. It feels clever. So you ship it, and for a while, things seem fine.
Then someone drops a screenshot into Slack and says, "Is this expected?"
That moment - the quiet uncertainty about whether what you're looking at is a bug or just the model being the model - is the actual problem, not the output itself. It’s the fact that nobody in the room can confidently say whether it's right or wrong.
At Omnea, we decided pretty early on that we weren't going to ship AI features based on gut feel. We wanted to treat them like production systems, with actual evidence that they work. This post is about how we got there and what we learned along the way building Omnea AI.
The mental model problem
Most of us grew up writing deterministic code. You write assert(add(2, 2) === 4) and if it passes, you're good.
That mental model is comfortable, but LLMs don't really care about your comfort.
The same input can give you slightly different wording, a different reasoning chain, a different tool call, or occasionally something completely wrong. The subtle bit is that not all of that variation is failure. Sometimes the model just phrases things differently and that's fine. Sometimes it picks a slightly different approach and that's also fine.
This means traditional testing doesn't map cleanly onto this stuff. The real question you have to answer before you can test anything is: what does "correct" actually mean for this feature? Until you've pinned that down precisely, you're not really engineering anything. You're just hoping it works, and hope isn't a great testing strategy.
The first time we properly broke it
Early on, we made what felt like a great improvement. We tweaked a system instruction and saw our summarisation score go up by about 8%. The outputs sounded smarter, cleaner, more confident. We were pretty pleased with ourselves.
Two days later we noticed tool-call accuracy had dropped by 11%.
The model sounded better, but it was objectively worse at doing what we needed it to do. That was the moment evals stopped feeling like a nice-to-have. LLM systems don't usually break loudly - they drift. A small prompt tweak here, a minor model update there, a "harmless" refactor. Everything still works, just slightly worse than before. Without something tracking that regression, you genuinely don't notice.
What an eval actually is
Before getting into specifics, it's worth explaining what we mean when we say "evals" in the context of AI feature development.
An eval is essentially a structured way of testing whether your LLM feature is doing what you want it to do. You can break it down in different ways, but I split them into three core components.
First, you need a 🧪 test dataset: a set of inputs paired with what you expect the correct output to be. These are your test cases - the scenarios you want your system to handle.
Second, you need 🥇 scorers: the logic that looks at what the model actually produced and decides whether it was right, partially right, or wrong. This could be a simple function that checks if the right tool was called, or it could be another LLM evaluating the quality of a summary.
Third, you need a 🏃🏽 runner: the thing that actually executes your test cases against your system, collects the outputs, passes them through the scorers, and aggregates the results into something you can reason about.
That's it. Conceptually it's not that different from a normal test suite - the difference is that your system under test is probabilistic, so you're working with pass rates and score distributions rather than binary pass/fail. Getting that mental model in place early on made everything else much easier for us.
Behaviour is what actually matters
When thinking about AI output, it’s common to judge it on whether the text looks good. But because our AI features sit inside structured product workflows, we need to consider more than just prose - they're triggering actions, calling tools, retrieving structured data. That means instead of asking "does this response look good?" we need to go further: did it call the correct tool? Did it pass the right arguments? Did it respect the constraints we gave it? Did it hallucinate fields that don't exist?
That shift from evaluating text to evaluating behaviour is what makes LLM systems actually testable. Here's a simplified version of what that looks like, where we are checking data and tool calls.
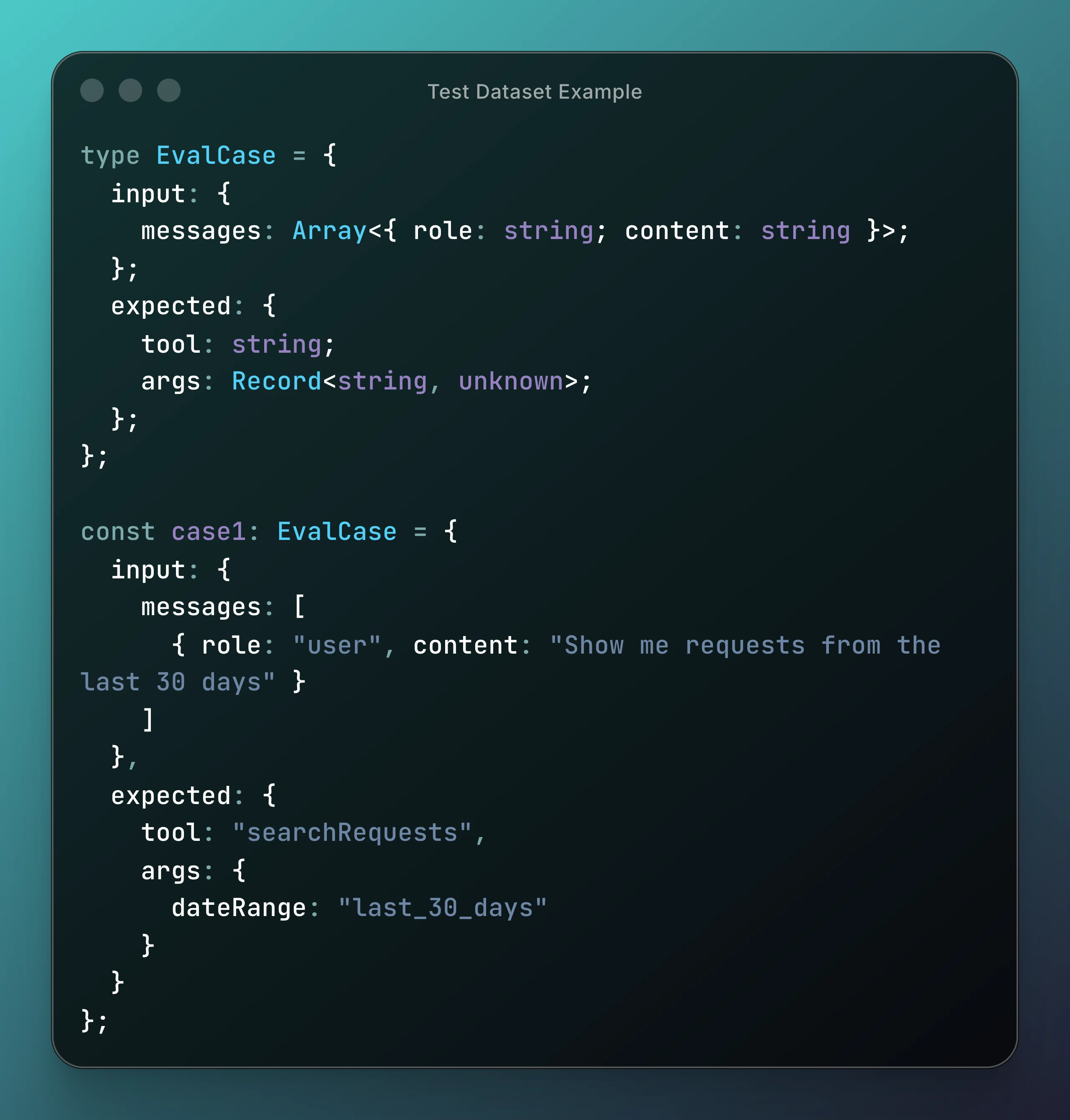
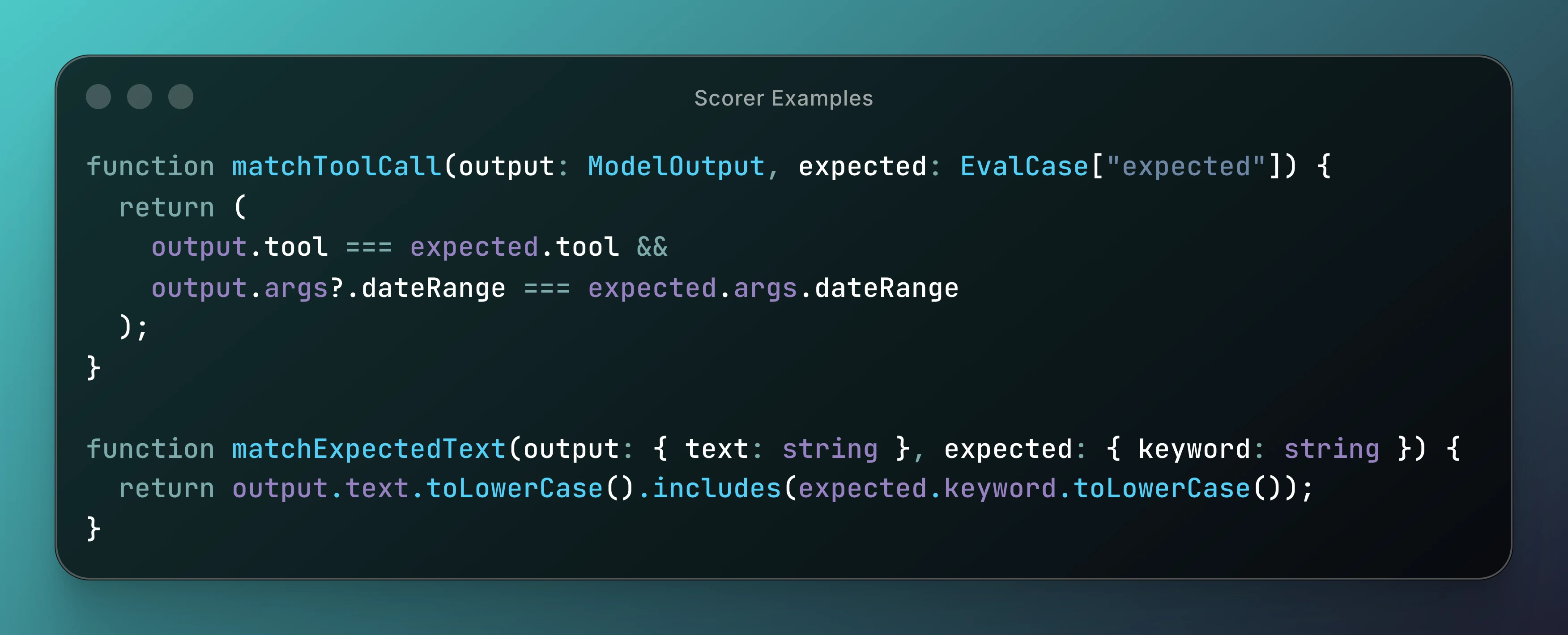
We assert structured intent, not just string equality. Once you've codified behaviour like this, experimentation becomes safe. You can swap models, adjust prompts, refactor tool schemas - and immediately see what you broke. That changes how aggressively you're able to iterate, which is the real payoff.
Capability evals vs regression evals
We split our evals into two categories, because they're answering two different questions.
Capability evals ask: does the system work at all? They cover core flows, high-risk ambiguity prompts, and cases that have historically broken. They're small and deliberately curated. If the system can't reliably pass them, it's not ready.
Regression evals ask the more dangerous question: did we make it worse? Every time we change a prompt template, a system instruction, a tool definition, or a model version, we rerun the suite. If tool-call accuracy drops from 92% to 85%, that's a regression, not a "maybe". Without this layer, LLM systems slowly decay - and the decay is subtle enough that you don't catch it until a customer does.
Using AI to score AI (yes, it feels a bit weird)
Not everything maps neatly to a tool call. Summaries, explanations and qualitative answers usually need more subjective evaluation. For these we sometimes use an AI-based scorer. In one example, we pass responses into another model that produces a 0 to 5 score, explains its reasoning, and flags weaknesses. How scoring and correctness is defined is totally up to you - it could be as simple as pass / fail, too.

Using AI to judge AI feels slightly wrong the first time you do it, but it works well when you have more open ended output with content that’s varied. Those are situations where simple deterministic string matching is too brittle and you’d usually want human judgement to decide whether it’s a good output or not. You can also combine and layer different evaluators to give an overall signal on quality, removing the dependence on any single measure of “correctness”. The goal isn't perfect truth but rather a stable signal across versions.
That said, eval systems introduce their own risks. One thing we're still thinking about is eval overfitting. The tighter your matcher logic gets, the more you risk optimising your prompts for the eval suite rather than for real-world behaviour. If your system gets better at passing tests but worse at helping users, you haven't actually improved anything.
We haven't solved that perfectly yet. Right now we mitigate it by periodically refreshing parts of our eval dataset with anonymised real user queries, and by keeping a small holdout-style set that we don't optimise against directly. Evals give you safety, but they don't remove the need for judgement.
Where Datadog fits in
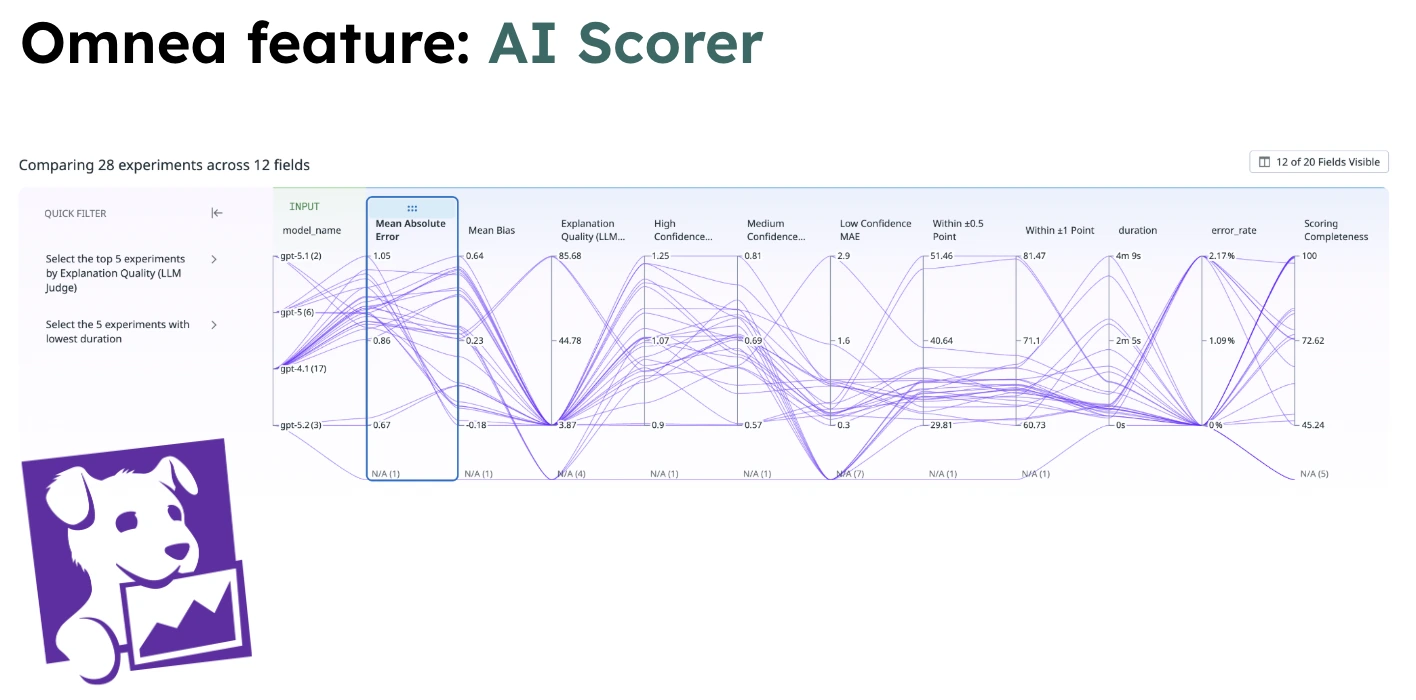
Evaluation without observability isn't enough. We integrate our eval runs into Datadog and treat experiments like production telemetry. For each experiment batch, we track tool-call accuracy, aggregate AI scores, latency, token usage, cost per request, and error rates.
This is where things get interesting. We've had scenarios where Model A improves reasoning score by +0.3, tool accuracy is unchanged, but latency goes up by 400ms and cost increases by 18%. We spent longer than we'd like to admit debating whether 400ms was noticeable enough to justify the improvement.
But that's sort of the point. The debate shifts from "I think this sounds better" to "is this trade-off worth it?" Because the data lives in dashboards, the whole team can see trends over time, catch regressions immediately, and understand the real-world cost of any given improvement. The AI feature stops being a black box and starts behaving like observable infrastructure. If your AI feature can't tell you whether it improved or regressed this week, it's not really a system - it's a gamble.

The critical shift
The biggest shift for me personally has been this: stop thinking of LLM features as prompts, and start thinking of them as distributed systems with probabilistic components. That means typed schemas around inputs and outputs, deterministic tool interfaces, explicit evaluation harnesses, versioned experiments, observability dashboards, and regression tracking.
It also means accepting something uncomfortable - you're never going to get 100%. The goal isn't perfection. The goal is measurable improvement over time. Even a 15-case eval suite will change how you build.
What this actually looks like day to day
From the outside, AI engineering can look a bit chaotic. Internally, our loop is fairly structured: identify a weakness via eval metrics, modify a prompt or system behaviour or tool schema, run an experiment batch, compare metrics in Datadog, and ship if the improvement is meaningful. Because regressions are visible, iteration feels safe. And when iteration feels safe, engineers move faster.
That's the counterintuitive bit. More rigour increases velocity.
The real question
The most important question isn't "is our AI impressive?" - it's "can we prove it's useful?"
We're building the evaluation systems, experimentation workflows, and observability tooling to answer that question with data rather than intuition. If you're interested in taming messy systems through smart engineering, you'd probably enjoy the problems we're working on. You can find our open roles on our careers page.
And if you've broken an LLM feature in production before - we should compare notes.



